
# 딕셔너리1. 딕셔너리란?
- key와 value를 한 쌍으로 갖는 자료형
- 불변한 key와 가변/불변적인 value로 맵핑된 순서가 없는 집합
- 인덱싱, 슬라이싱이 불가능
2. 딕셔너리 선언
# 딕셔너리명 = {key : value, key : value...}
a = {} # 빈 딕셔너리
b = {'name' : 'phj'} # 이름정보(문자열)을 담은 딕셔너리
c = {1 : 'phj', 2 : 23} # 하나의 딕셔너리에는 다양한 자료형을 담을 수 있다.
d = {'name' : ['홍모', '승광', '태호']} # value값으로 리스트 형태의 자료를 담을 수 있다.
# 명확하게 뭔가를 정의하고 싶을 때 딕셔너리를 사용print(a)
print(b)
print(c)
print(d)
# {}
# {'name': 'phj'}
# {1: 'phj', 2: 23}
# {'name': ['홍모', '승광', '태호']}
type(d)
# dict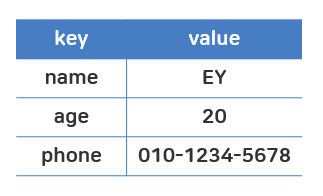
# 위 정보를 담은 딕셔너리 선언해보기
info = {"name" : "phj", "age" : 26, "phone" : "010-0000-0000"}
info
# {'name': 'phj', 'age': 26, 'phone': '010-0000-0000'}
3. 딕셔너리 값 추가
- 없는 키 값 : 새로운 값
info["birth"] = "03/30"
info
# {'name': 'phj', 'age': 26, 'phone': '010-0000-0000', 'birth': '03/30'}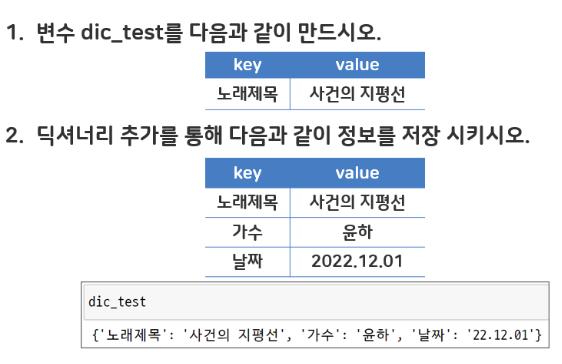
dic_test = {"노래제목" : "사건의 지평선"}
dic_test["가수"] = "윤하"
dic_test["날짜"] = "2022.12.01"
dic_test
# {'노래제목': '사건의 지평선', '가수': '윤하', '날짜': '2022.12.01'}
4. 딕셔너리 값 가져오기(데이터에 접근하기)
info
# info에서 이름 가져오기
# 딕셔너리명[키] => 키에 해당하는 value를 반환해줌
info["name"]
info["phone"]- get() : 데이터에 접근할 때 사용하는 함수 .get(키)
info.get("name")
# 'phj'
4.1 딕셔너리 데이터 접근 방법 비교
- 딕셔너리명[키] vs 딕셔너리명.get(키)
# 없는 키를 사용하여 데이터를 찾을 때
info["address"]
# KeyError: 'address'test = info.get("address")
print(test)
# None# 예외 처리 try ~ except
try :
address = info["address"]
print(address)
except KeyError :
print("없는 키 값입니다.")
# 없는 키 값입니다.
5. 딕셔너리 관련 함수 : 데이터에 접근하는 방법들
5.1 딕셔너리 키 값만 가져오기
info
# {'name': 'phj', 'age': 26, 'phone': '010-0000-0000', 'birth': '03/30'}
info.keys()
# dict_keys(['name', 'age', 'phone', 'birth'])
# name이라는 키에 접근하고 싶을 때 (키 값을 인덱싱 하겠다.)
# 리스트로 형변환해서 키 값들을 인덱싱으로 활용할 수 있음
list(info.keys())[0]
# 'name'5.2 딕셔너리 value값만 가져오기
info.values()
# dict_values(['phj', 26, '010-0000-0000', '03/30'])
# 생일 값에 접근하고 싶을 때
list(info.values())[3]
# '03/30'5.3 딕셔너리 key, value 모두 가져오기
info.items()
#dict_items([('name', 'phj'), ('age', 26), ('phone', '010-0000-0000'), ('birth', '03/30')])
list(info.items())
# [('name', 'phj'), ('age', 26), ('phone', '010-0000-0000'), ('birth', '03/30')]
for i in info.items() : # 튜플 형태의 패킹된 상태로 출력
print(i)
# ('name', 'phj')
# ('age', 26)
# ('phone', '010-0000-0000')
# ('birth', '03/30')# 언패킹된 형태로 출력해보기
for key, value in info.items() :
print(key, value)
# name phj
# age 26
# phone 010-0000-0000
# birth 03/30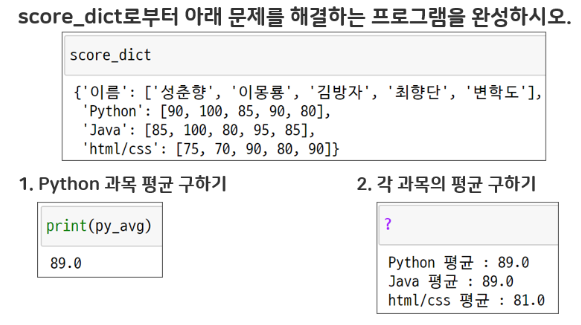
score_dict = {"이름" : ['성춘향', '이몽룡', '김방자', '최향단', '변학도'],
"Python" : [90, 100, 85, 90, 80],
"Java" : [85, 100, 80, 95, 85],
"html/css" : [75, 70, 90, 80, 90]}# 방법 1)
result_p = 0
result_j = 0
result_h = 0
for i in range(0, 5) :
result_p += score_dict["Python"][i]
result_j += score_dict["Java"][i]
result_h += score_dict["html/css"][i]
avg_p = result_p//5
avg_j = result_j//5
avg_h = result_h//5
print(avg_p, avg_j, avg_h)# 방법 2)
result_p = 0
result_j = 0
result_h = 0
for i in list(score_dict.values())[1] :
result_p += i
avg_p = result_p//5
print(avg_p)
for i in list(score_dict.values())[2] :
result_j += i
avg_j = result_j//5
print(avg_j)
for i in list(score_dict.values())[3] :
result_h += i
avg_h = result_h//5
print(avg_h)# 방법 3)
# 이름을 빼고 과목명만 가져오기 위해서 리스트로 형변환
# => 인덱싱, 슬라이싱을 하기 위해서 형변환을 하는 것.
avg = 0 # 평균값을 담아줄 변수
for i in list(score_dict.keys())[1:] :
avg = sum(score_dict[i])//len(score_dict[i])
print(f"{i}평균 : {avg}")# 방법 4)
avg = 0
for i in score_dict.keys() :
if i != '이름' :
avg = sum(score_dict[i])//len(score_dict[i])
print(f"{i}평균 : {avg}")
6. 딕셔너리 값 삭제
- del키워드
- clear()
# del 키워드
info
# 폰 정보 삭제하기
del info['phone'] # 삭제됨과 동시에 초기화
info
# {'name': 'phj', 'age': 26, 'birth': '03/30'}# 값(데이터)를 모두 삭제할 때
info.clear()
info
# {}




댓글