
시스템 환경변수
[Path에 경로 추가]

'찾아보기'버튼 클릭 후
내PC -> C드라이브 -> Program Files -> Java -> jdk1.8.0_202 -> bin
[Java Home] 만들어주기
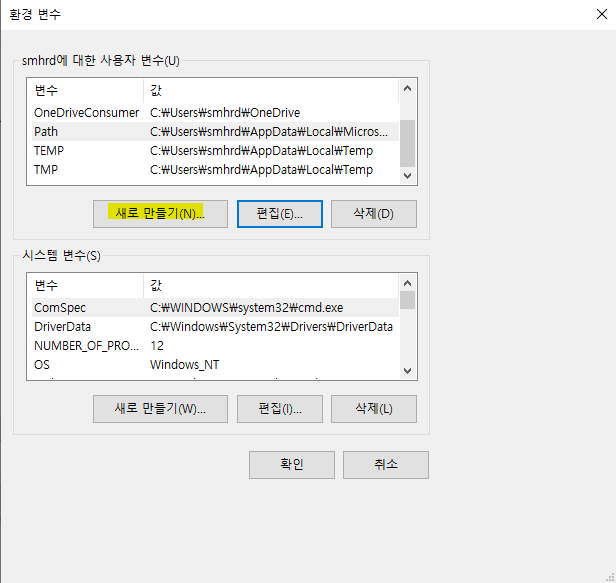

'디렉토리 찾아보기'버튼 클릭 후
아래 경로로 확인!
내PC -> C드라이브 -> Program Files -> Java -> jre1.8.0_202
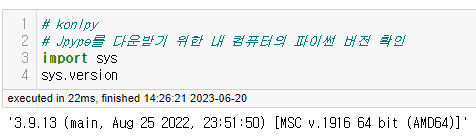
https://www.lfd.uci.edu/~gohlke/pythonlibs/#jpype
Archived: Python Extension Packages for Windows - Christoph Gohlke
Archived: Python Extension Packages for Windows - Christoph Gohlke by Christoph Gohlke. Updated on 26 June 2022 at 07:27 UTC. This page provides 32 and 64-bit Windows binaries of many scientific open-source extension packages for the official CPython
www.lfd.uci.edu

다운받은 파일을 아래 경로로 이동

아나콘다 prompt 창 열어주기

아나콘다 prompt 창에서 아래 3줄 입력해주기

한글이 되는지 확인하는 과정
아래와 같이 ['안녕'] 문구만 나와야 정상!

!pip install konlpy
from konlpy.tag import Okt
okt = Okt()
okt.morphs('아버지가방에들어가신다')
# morphs : 가지고 있는 문장을 명사단위로 쪼개주는 기능
# 한글은 띄어쓰기 단위로 토큰화를 진행하면 의미가 손실
# 토큰화를 할 수 있는 모듈을 따로 사용해야 함. --> 영어와는 다른 형태로 분류를 사용
konlpy 간단하게 사용해보기
text = ['나는 어제 버스를 탔다.',
'어제 버스는 만원이었다.',
'어제 나는 영화를 보았다.',
'어제 본 영화는 정말 재미있었다']
Countvectorizer(BOW)
from sklearn.feature_extraction.text import CountVectorizer
CV = CountVectorizer()
# 토큰화, 단어사전 구축
CV.fit(text)
# 기본값 = 띄어쓰기 단위로 토큰화
CV.vocabulary_
Countvectorizer + Okt
# 함수생성
def myToken(text) :
return okt.nouns(text) # 명사를 추출해서 토큰화
# 모델 생성
cv_okt = CountVectorizer(tokenizer=myToken)
# 학습
cv_okt.fit(text)
cv_okt.vocabulary_
# 명사만 추출한 것은 확인할 수 있음
# 토큰화 도구 : morphs
# okt.morphs : 형태소별로 구분
okt.morphs(text[0]) # 리스트로 값이 저장되어 있으므로 하나의 값만 넣어서 확인
# okt.pos : 토큰화한 후 어떤 형태소를 가지고 있는지 확인
okt.pos(text[0])
# okt.tagset : 표현할 수 있는 전체 형태소를 출력
okt.tagset
# Kkma : 더 많은 형태소로 구분, 시간이 많이 걸림
from konlpy.tag import Kkma
kkma = Kkma()
kkma.tagset
# 데이터 전처리때 시간적 여유가 많다면 사용
네이버 영화리뷰 데이터셋 감성분석
import numpy as np
import pandas as pd
데이터 불러오기
text_train = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/data/ratings_train.csv', encoding='utf-8')
text_test = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/data/ratings_test.csv', encoding='utf-8')
text_train
# label : 0은 부정, 1은 긍정
text_test
# 결측치 확인
text_train.info()
# 결측치가 있는 행을 삭제
text_train.dropna(inplace=True) # 5개가 삭제
text_test.dropna(inplace=True) # 3개가 삭제
text_train.info()
text_test.info()
# 문제만 토큰화시키기 위해서 문제와 정답을 나눠주기
X_train = text_train['document']
X_test = text_test['document']
y_train = text_train['label']
y_test = text_test['label']
# tf-idf 적용
토큰화 및 수치화
from sklearn.feature_extraction.text import TfidfVectorizer
# pipeline으로 연결
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
pipe_model = make_pipeline(TfidfVectorizer(tokenizer=myToken),
LogisticRegression())
# 학습
pipe_model.fit(X_train, y_train)
pipe_model.score(X_train, y_train)
pipe_model.score(X_test, y_test)
# pipe_model --> tf-idf(단어사전), LogisticRegression(가중치-coef_)
tfidf = pipe_model.steps[0][1] # 단어사전
logi = pipe_model.steps[1][1] # 가중치
word_weights = logi.coef_[0]
voca = tfidf.vocabulary_
df= pd.DataFrame([voca.keys(),voca.values()])
# 번호를 인덱스로 사용하기 위해 전치,행과 열을 뒤집겠다
df =df.T
# 1번 컬럼을 기준으로 정렬
df = df.sort_values(by=1)
# 가중치(coef) 컬럼 추가
df['coef'] = word_weights
df = df.sort_values(by='coef',ascending=False)
df
# 긍정에 영향을 주는 단어
df.head(10)
# 부정에 영향을 주는 단어
df.tail(10)'Computer Engineering > 머신러닝' 카테고리의 다른 글
| 영화리뷰 분석 (0) | 2023.06.20 |
|---|---|
| Logistic_SVM_손글씨 숫자 데이터 분류 실습 (0) | 2023.06.19 |
| 선형회귀_LinearRegression_보스턴 주택가격 실습 (0) | 2023.06.19 |
| 선형회귀 (0) | 2023.06.16 |
| Ensemble 유방암 데이터 분류 실습 (0) | 2023.06.15 |

댓글