
판다스 공식 사이트 : https://pandas.pydata.org
Pandas 객체(자료구조)
- 1차원 : 시리즈(Series)
- 2차원 : 데이터프레임(DataFrame)
import pandas as pd1차원 시리즈 생성
list 이용
# 도시별 인구 수를 나타내는 Series 생성
pop = pd.Series([9602000, 3344000, 1488000, 2419000])
pop0 9602000
1 3344000
2 1488000
3 2419000
dtype: int64# 시리즈 데이터에 인덱스를 지정하여 생성
pop = pd.Series([9602000, 3344000, 1488000, 2419000],
index=["서울", "부산", "광주", "대구"])
pop서울 9602000
부산 3344000
광주 1488000
대구 2419000
dtype: int64# 딕셔너리를 이용해서 시리즈 생성하기
# 면적에 대한 정보 생성
# 딕셔너리명 = {'key1':'value1', 'key2':'value2',...}
area = pd.Series({'서울':605.2, '부산':770.1, '광주':501.1, '대구':883.5})
area서울 605.2
부산 770.1
광주 501.1
대구 883.5
dtype: float64
시리즈 데이터 속성 확인
# 1. value값만 확인하고 싶을 때
pop.values # numpy 배열형태로 반환array([9602000, 3344000, 1488000, 2419000], dtype=int64)# 2. index 값을 확인하고 싶을 때
pop.indexIndex(['서울', '부산', '광주', '대구'], dtype='object')# 3. 데이터 타입 확인하고 싶을 때
pop.dtypedtype('int64')
시리즈 이름 지정하기
- 시리즈의 이름은 DataFrame의 컬럼명이 된다.
pop서울 9602000
부산 3344000
광주 1488000
대구 2419000
dtype: int64
pop.name = "2020년 인구"
pop서울 9602000
부산 3344000
광주 1488000
대구 2419000
Name: 2020년 인구, dtype: int64pop.index.name = "도시"
pop도시
서울 9602000
부산 3344000
광주 1488000
대구 2419000
Name: 2020년 인구, dtype: int64
시리즈 데이터 갱신(수정), 삭제, 추가
# 갱신(수정) => 1. 인덱스 위치에 접근, 2. 값을 대입
# 도시 => 지역으로 변경하기
pop.index.name="지역"
pop지역
서울 9602000
부산 3344000
광주 1488000
대구 2419000
Name: 2020년 인구, dtype: int64pop["서울"] = 8000000
pop지역
서울 8000000
부산 3344000
광주 1488000
대구 2419000
Name: 2020년 인구, dtype: int64# 삭제 : drop()
pop.drop("대구", inplace=True) # 데이터를 삭제하고 원래 위치에 반영(초기화)
# inplace의 기본값은 False
# pop = pop.drop('대구') # 삭제한 결과를 원래의 변수에 대입한 결과와 동일pop지역
서울 8000000
부산 3344000
광주 1488000
Name: 2020년 인구, dtype: int64# 추가 : 없는 키 값을 불러주고 값을 대입
# '나주' = 1000000
pop['나주'] = 1000000pop지역
서울 8000000
부산 3344000
광주 1488000
나주 1000000
Name: 2020년 인구, dtype: int64# 대구 ==> 나주로 변경, 면적 정보 300.1
area['대구'] = '나주'
area['나주'] = 300.1
area.drop('대구', inplace=True)area서울 605.2
부산 770.1
광주 501.1
나주 300.1
dtype: object# area 시리즈 이름 = 면적(㎢), 인덱스 이름 = 지역
area.name = '면적(㎢)'
area.index.name = '지역'area지역
서울 605.2
부산 770.1
광주 501.1
나주 300.1
Name: 면적(㎢), dtype: object
시리즈 병합 : concat()
# axis = 0 : 행방향
# axis = 1 : 열방향
df = pd.concat([pop, area]) # axis 기본값 ==> 행방향
df지역
서울 8000000
부산 3344000
광주 1488000
나주 1000000
서울 605.2
부산 770.1
광주 501.1
나주 300.1
dtype: object# axis = 0 : 행방향
# axis = 1 : 열방향
df = pd.concat([pop, area], axis=1) # 열방향으로 지정
df
# 시리즈의 이름이 컬럼명이 된 것도 확인
2차원 데이터프레임(DataFrame) 생성
# list 이용
data = [[1488000, 501.1], [2419000, 883.5], [1400000, 883.5], [2951000, 1065.2]]# 이중리스트를 활용하여 2차원 데이터프레임 생성
df3 = pd.DataFrame(data)
df3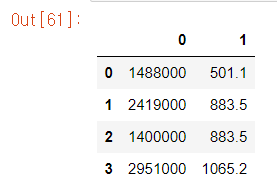
# 인덱스명, 컬럼명 설정
df3 = pd.DataFrame(data, index=['광주', '대구', '전주', '인천'],
columns=['2020 인구', '면적(㎢)'])
df3
# 딕셔너리를 이용하여 데이터프레임 생성
# 컬렴명이 키값
data = {'2020 인구':[1488000, 2419000, 14000000, 2951000],
"면적(㎢)" : [501.1, 883.5, 883.5, 1065.2]}
df4 = pd.DataFrame(data, index=["광주", "대구", "전주", "인천"])
df4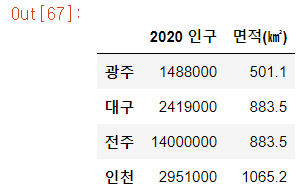
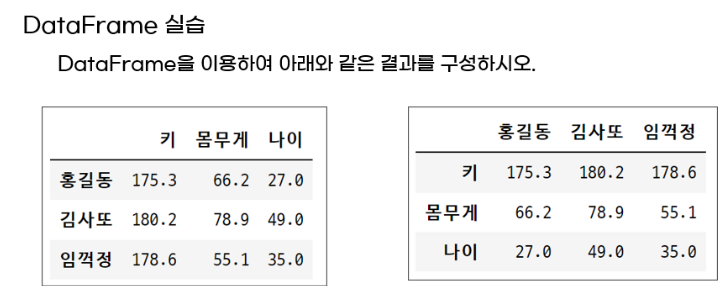
# 리스트 이용
data5 = [[175.3, 66.2, 27.0], [180.2, 78.9, 49.0], [178.6, 55.1, 35.0]]
df5 = pd.DataFrame(data5, index=['홍길동', '김사또', '임꺽정'],
columns=['키', '몸무게', '나이'])
df5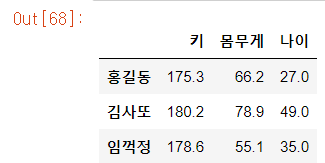
# 딕셔너리 이용
data6 = {'키':[175.3, 180.2, 178.6], '몸무게':[66.2, 78.9, 55.1], '나이':[27.0, 49.0, 35.0]}
df6 = pd.DataFrame(data6, index=['홍길동', '김사또', '임꺽정'])
df6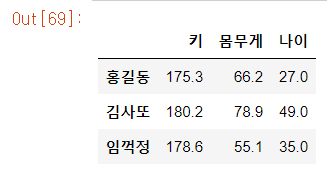
# 행과 열을 전환하는 키워드 .T(전치 => transpose)
df5_t = df5.T
df5_t
# .T의 결과는 계속 바뀔 수 있다.
# df5_t.T는 원래 결과값으로 돌아옴.
Pandas 데이터 접근하기 : 인덱싱 & 슬라이싱
시리즈 인덱싱
stud1 = pd.Series({'java':95, 'python':100, 'db':85, 'html/css':70})
stud1java 95
python 100
db 85
html/css 70
dtype: int64# 인덱싱으로 java 데이터 접근하기
stud1['java']
stud1[0]95# 여러 개의 과목데치터에 한 번에 인덱싱하기
# java, db 데이터 접근
stud1[['java', 'db']]
stud1[[0, 2]]
stud1[::2]java 95
db 85
dtype: int644.2 시리즈 슬라이싱
stud1java 95
python 100
db 85
html/css 70
dtype: int64# python ~ db 데이터 접근하기
stud1['python':'db'] # 문자열 슬라이싱은 끝값을 포함함
stud1[1:3] # 인덱스 번호로 접근할 땐 끝값이 포함이 안된다.+1python 100
db 85
dtype: int64# print(), display() ==> 출력결과 비교
# java ~ python 까지 데이터 접근하기
print(stud1['java':'python'])
print(stud1['python':'db'])
display(stud1['java':'python']) # display는 문단 구분이 가능
display(stud1['python':'db'])java 95
python 100
dtype: int64
python 100
db 85
dtype: int64
java 95
python 100
dtype: int64python 100
db 85
dtype: int644.3 시리즈 불리언 인덱싱
# stud1 안의 데이터에서 85점 이상인 과목 확인하기
stud1[stud1>=85]java 95
python 100
db 85
dtype: int64# 85점 이상인 과목만 접근하기
stud1[stud1>=85].indexIndex(['java', 'python', 'db'], dtype='object')# 90점 미만인 과목 접근하기
stud1[stud1<90].index
stud1.index[stud1<90]Index(['db', 'html/css'], dtype='object')# 75점 이상 90점 미만인 과목 접근하기
# 불리언 인덱싱에서 두 개의 조건을 연결 - 비트연산자 &, | 사용
stud1[(stud1>=75)&(stud1<90)].indexIndex(['db'], dtype='object')4.4 2차원 데이터프레임 데이터 접근
df_std = pd.DataFrame({'java':[95, 85], 'python':[100, 95], 'db':[85, 85], 'html/css':[70, 75]},
index=['준화', '기쁨'])
df_std
# python 성적 데이터에 접근
df_std['python'] # 1차원 시리즈
# 2차원에서 []열고 값을 입력하면 컬럼이라고 인식
# 열에 대한 인덱싱을 수행준화 100
기쁨 95
Name: python, dtype: int64df_std[['db']]
# 데이터프레임으로 출력하고자 하면, 하나의 열이지만 [[]] => 대괄호 2개로 표현하면 가능
# [[]] => 행과 열을 가져오므로 대괄호 2개 사용
# 여러 개의 컬럼 데이터 접근하기
# java, python 데이터에 접근
df_std[['java', 'python']]
# 슬라이싱으로 접근하기
# python ~ html/css 까지 접근하기
# [] : 행데이터
# [[]] : 열데이터
df_std['python':'html/css'] # ==> 행으로 접근, 행인덱싱
# df_std[컬럼명]
df_std['python'] # ==> 열로 접근
4.5 loc, iloc 인덱서
- 판다스에서 특정 행(row), 열(column)에 접근할 때 사용
- loc 인덱서
- 문자열 기반의 데이터에 접근(실제 인덱스 값을 사용하여 데이터 접근)
- 행접근 : df.loc[행], df.loc[시작행:끝행], df.loc[[행1, 행3, 행5]]
- 열접근 : df.loc[:, 열], df.loc[:, 시작열:끝열], df.loc[:, [열1, 열3, 열5]]
- iloc 인덱서
- numpy array에서 제공하는 인덱스 번호 기반으로 데이터 접근(눈에 보이지 않는 인덱스에도 접근)
- 행접근 : df.iloc[행인덱스], df.iloc[시작행인덱스:끝행인덱스+1], df.iloc[[행1인덱스, 행3인덱스]]
- 열접근 : df.iloc[:, 열인덱스], df.iloc[:, 시작열인덱스:끝열인덱스+1], df.iloc[:, [열1인덱스, 열3인덱스]]
- 배열.loc[행, 열], 배열.iloc[행, 열]
- loc : location - 위치기반
- iloc : int location - 인덱스 번호 기반
# python ~ html/css 까지 접근하기
df_std.iloc[:, 1:]
df_std.loc[:, 'python':'html/css']
# db 컬럼에 접근
# loc 사용하여 접근
df_std.loc[:, 'db']
df_std.iloc[:, 2]
df_std.loc[:, ['db']]
df_std.iloc[:, [2]]준화 85
기쁨 85
Name: db, dtype: int64
# 준화씨의 데이터 접근하기
df_std.iloc[[0], :]
df_std.loc[['준화'], :]
# 데이터 프레임을 기쁨, 준화 순서로 보이게 출력하기
df_std.loc[['기쁨', '준화']]
df_std.iloc[[1, 0]]
df_std.iloc[::-1]
4.6 데이터프레임 불리언 인덱싱
# 'python'의 성적이 95점 이상인 사람의 수는 몇 명일까?
df_std[df_std['python']>=95].shape[0]
# 인덱스로 접근해서 길이함수 이용
len(df_std[df_std['python']>=95].index)
# 인덱스의 요소갯수로 확인
df_std[df_std['python']>=95].index.size2# java가 85점 이상인 사람의 html/css 점수 출력해보기
# 1. java >= 85
df_std[df_std['java']>=85]
# 2. html/css 점수 접근
df_std[df_std['java']>=85]['html/css']
df_std[df_std['java']>=85].loc[:, 'html/css']
df_std[df_std['java']>=85].iloc[:, [3]]
df_std[df_std['java']>=85].iloc[:, -1]
# 3. 불리언 인덱싱 사용해서 출력해보기
df_std.loc[df_std['java']>=85, 'html/css']준화 70
기쁨 75
Name: html/css, dtype: int64
5 시리즈 간 연산
pop지역
서울 8000000
부산 3344000
광주 1488000
나주 1000000
Name: 2020년 인구, dtype: int64area지역
서울 605.2
부산 770.1
광주 501.1
대구 883.5
Name: 면적(㎢), dtype: float64# 연산 수행하기
print(pop+area)
print(pop-area)
print(pop*area)지역
광주 1488501.1
나주 NaN
대구 NaN
부산 3344770.1
서울 8000605.2
dtype: float64
지역
광주 1487498.9
나주 NaN
대구 NaN
부산 3343229.9
서울 7999394.8
dtype: float64
지역
광주 7.456368e+08
나주 NaN
대구 NaN
부산 2.575214e+09
서울 4.841600e+09
dtype: float64# 인구밀도 = 인구수/면적
dense = pop/area
dense
# df3 데이터 프레임에 컬럼 추가하기
df2["인구밀도"] = dense
df2
6 유용한 함수
6.1 데이터 정렬 함수
- sort_values : 데이터 값을 기준으로 정렬 (기본값 : 오름차순)
- sort_index : 인덱스 값을 기준으로 정렬
# 데이터 값 정렬
df2['인구밀도'].sort_values(ascending=False)서울 15865.829478
부산 4342.293209
광주 2969.467172
대구 2737.973967
Name: 인구밀도, dtype: float64# 인덱스 정렬
df2['인구밀도'].sort_index(ascending=False)서울 15865.829478
부산 4342.293209
대구 2737.973967
광주 2969.467172
Name: 인구밀도, dtype: float64# 데이터의 컬럼명을 확인하는 키워드
df2.columnsIndex(['2020년 인구', '면적(㎢)', '인구밀도'], dtype='object')# 컬럼명을 기준으로 정렬
df2['2020년 인구'].sort_values(ascending=False)서울 9602000
부산 3344000
대구 2419000
광주 1488000
Name: 2020년 인구, dtype: int64# 2개의 컬럼을 정렬하고자 할 때
df2.sort_values(by=['2020년 인구', '면적(㎢)'], ascending=[False, True])
df2.sort_values(by=['서울'], axis=1)
data = {'c1':[10,20,10,20], 'c2':[4,3,2,1]}
df7 = pd.DataFrame(data)
df7
df_s = df7.sort_values(by=['c1', 'c2'], ascending=[False, True])
df_s
6.2 카운팅하는 함수
df2['면적(㎢)'].value_counts()605.2 1
770.1 1
501.1 1
883.5 1
Name: 면적(㎢), dtype: int64# 데이터에만 접근
df2['면적(㎢)'].value_counts().valuesarray([1, 1, 1, 1], dtype=int64)6.3 데이터 삭제하는 함수
# df2 => 인구밀도 컬럼 삭제하기
df2.drop('인구밀도', axis=1, inplace=True)
# axis = 0 : 행방향
# axis = 1 : 열방향
# inplace = True => 삭제된 결과를 초기화df2
# 여러 개(광주, 나주)를 지우고 싶을 때
df2.drop(['광주', '나주'], axis=0, inplace=True)df2
6.4 데이터를 불러오는 함수
# 한글을 불러오는 encoding 방식 => cp949, utf-8, euc-kr
score = pd.read_csv('data/score.csv', index_col='과목', encoding='cp949')
score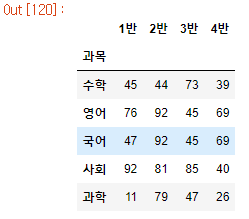
# 데이터 확인하기
# 크기 확인 : shape
score.shape
# 데이터 타입 : dtype
# 데이터 프레임의 데이터 타입의 확인은 각각의 데이터로 접근하여 확인한다.
score['1반'].dtype
# 컬럼명(이름) 확인
score.columns
# 행이름 확인
score.index(5, 4)dtype('int64')Index(['1반', '2반', '3반', '4반'], dtype='object')Index(['수학', '영어', '국어', '사회', '과학'], dtype='object', name='과목')6.5 데이터의 정보를 출력하는 함수
score.info()<class 'pandas.core.frame.DataFrame'>
Index: 5 entries, 수학 to 과학
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 1반 5 non-null int64
1 2반 5 non-null int64
2 3반 5 non-null int64
3 4반 5 non-null int64
dtypes: int64(4)
memory usage: 200.0+ bytes# 결측치 개수 확인해보기
score.isnull().sum()1반 0
2반 0
3반 0
4반 0
dtype: int646.6 결측치인지 아닌지 확인하는 함수
score.isnull()
# 결측치 0 : True, 결측치 X : False
6.7 총합을 구하는 함수
score.isnull().sum(axis=1)과목
수학 0
영어 0
국어 0
사회 0
과학 0
dtype: int646.8 학급별 순위(성적이 높은 순부터)

score.sum().sort_values(ascending=False)2반 388
3반 295
1반 271
4반 243
dtype: int646.9 과목별 합계를 계산해서 '합계'컬럼으로 추가하기
socre['합계'] = score.sum(axis=1)
6.10 과목별 평균을 계산하여 '평균' 컬럼 추가하기
a = score.columns[:4].size
len(score.columns[:4])4avg = result/ascore["평균"] = avg
score
score['평균'] = score.loc[:, '1반':'4반'].mean(axis=1)
score6.11 반 평균을 계산해서 새로운 행으로 추가하기
# 인덱서를 이용해서 행 추가
score.loc['반평균', :] = score.mean()
score
6.12 최댓값, 최솟값 구하는 함수
- max. min
# max
score.max(axis=1)
# min
score.min(axis=1)과목
수학 39.0
영어 45.0
국어 45.0
사회 40.0
과학 11.0
반평균 48.6
dtype: float646.13 1 ~ 4반까지 점수 중 과목별 가장 큰 값과 가장 작은 값의 차이를 구하시오
# loc
max1 = score.loc[:'과학', :'4반'].max(axis=1)
min1 = score.loc[:'과학', :'4반'].min(axis=1)
#iloc
max2 = score.iloc[:5, :4].max(axis=1)
min2 = score.iloc[:5, :4].min(axis=1)
max1-min1과목
수학 34.0
영어 47.0
국어 47.0
사회 52.0
과학 68.0
dtype: float646.14 cut 함수 : 수치형 데이터 --> 범주형 데이터로 변환
ages = [0, 2, 10, 21, 23, 37, 31, 61, 20, 41, 32, 100]
bins = [-1, 15, 30, 40, 60, 100] # 구간 설정
# 구간 -> 시작값은 포함하지 않고 끝값은 포함됨.
labels = ['미성년자', '청년', '장년', '중년', '노년']
cats = pd.cut(ages, bins=bins, labels=labels)
cats['미성년자', '미성년자', '미성년자', '청년', '청년', ..., '노년', '청년', '중년', '장년', '노년']
Length: 12
Categories (5, object): ['미성년자' < '청년' < '장년' < '중년' < '노년']pd.Series(cats)0 미성년자
1 미성년자
2 미성년자
3 청년
4 청년
5 장년
6 장년
7 노년
8 청년
9 중년
10 장년
11 노년
dtype: category
Categories (5, object): ['미성년자' < '청년' < '장년' < '중년' < '노년']6.15 groupby() : 데이터를 그룹별로 묶어서 집계낼 수 있게 하는 함수
s1 = pd.Series([1,0,1,0,1])
s2 = pd.Series(['female','female','male','male','female'])
s3 = pd.Series([1,2,3,4,5])
ti = pd.concat([s1, s2, s3], axis=1)ti.columns = ['Servived', 'Sex', 'PassengerId']
ti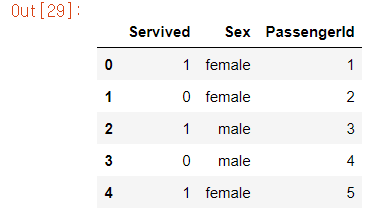
# 성별에 따른 생존자 수 확인하기
ti[['Servived', 'Sex']].groupby('Sex').sum()
# 성별을 기준으로 groupby함수에 명시하여 묶어서 결과를 반환
# 성별에 따른 생존자 수 / 사망자 수 확인하기
# count()
ti.groupby(by=['Sex', 'Servived']).count()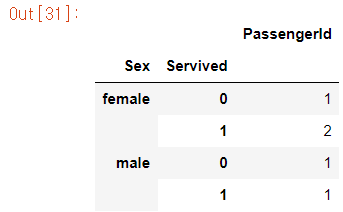
'언어 > Python' 카테고리의 다른 글
| 파이썬 라이브러리 시험 (0) | 2023.04.05 |
|---|---|
| Matplotlib (0) | 2023.04.04 |
| Numpy 실습 - 영화 평점데이터 분석하기 (0) | 2023.04.03 |
| Numpy (0) | 2023.04.01 |
| 모듈 (0) | 2023.03.31 |



댓글