
import warnings
warnings.filterwarnings(action='ignore') # 경고창 무시
y = [2, 4, 6, 8]
plt.plot(y)
plt.show() # 그래프를 출력해주는 함수 : show()x = [1, 2, 3, 4]
y = [2, 4, 6, 8]
plt.plot(x, y)
plt.show()# 선 스타일
plt.plot(y, ls='--') # 라인스타일 => ls로 표현
plt.show()# 마커포인트 : marker
plt.plot(y, marker='o')
plt.show()
# 선 두께 : line width => lw
plt.plot(y, marker='o', lw=5)
plt.show()
# 선 색상 : line color => c
plt.plot(y, marker='o', lw=2, c='r')
plt.show()
# marker의 컬러 지정하기
plt.plot(y, marker='o', lw=2, c='red', mfc='g')
plt.show()
x = np.arange(7)
# 0~6 범위 내의 배열 데이터 생성하는 함수(numpy 모듈을 이용)
y = [1,4,5,8,9,5,3]
plt.plot(x, y, ls='--', marker='s', c='g', mfc='b')
plt.show()
# 그래프 사이즈 조정하기
plt.figure(figsize=(5, 3))
plt.plot(x, y, ls='--', marker='s', c='g', mfc='b')
plt.show()
그래프 옵션 설정
# 그림의 범위 지정 : lim -> xlim, ylim
plt.plot(x, y, ls='--', marker='s', c='g', mfc='b')
# zoomout
# plt.xlim(-2, 10) # x축의 범위 제한
# plt.ylim(-3, 12) # y축의 범위 제한
# plt.show()
# zoomin
plt.xlim(2, 7)
plt.ylim(3, 8)
plt.show()
# zoomin/out => lim을 사용하여 x축과 y축의 범위를 제한하면 zoomin/out의 효과를 확인할 수 있음.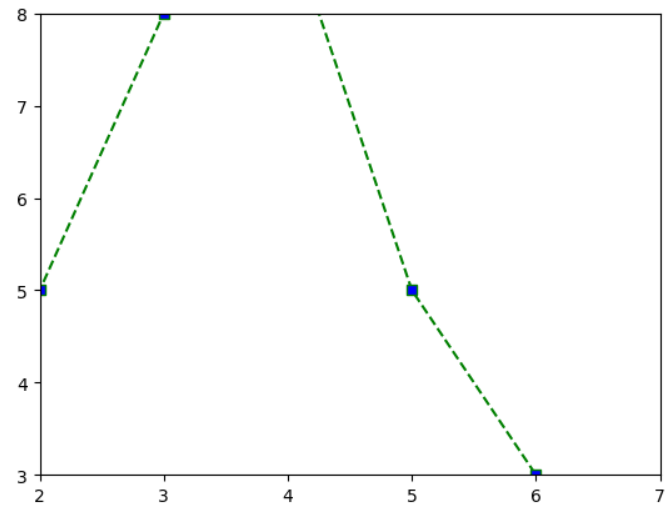
# 틱 설정 - x, y 축 표시값 설정하는 기능
plt.plot(x, y, ls='--', marker='s', c='g', mfc='b')
plt.xticks([0, 3, 6])
plt.yticks([1, 5, 9])
plt.show()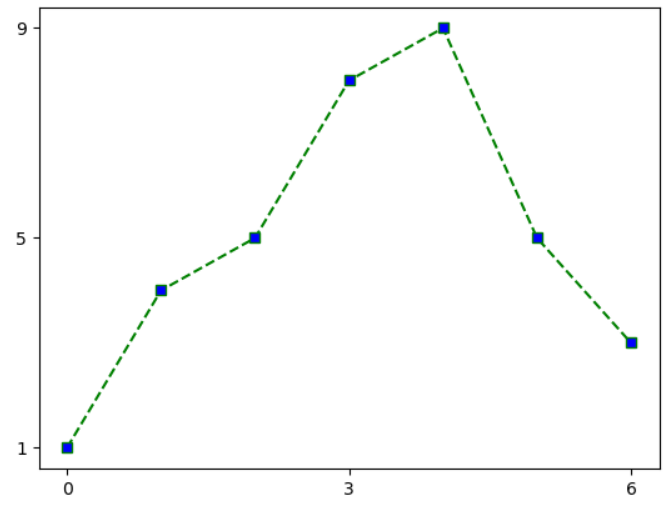
# 눈금선 표시 : grid()
plt.plot(x, y, ls='--', marker='s', c='g', mfc='b')
plt.grid()
plt.show()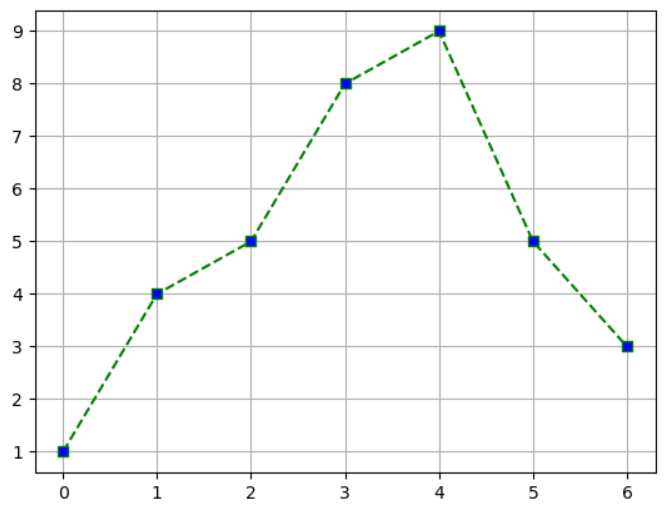
# 여러 개의 그래프 출력하기
x1 = [1,2,3,4]
x = [1,2,3,4]
y = [2,4,6,8]
z = [3,6,9,12]
plt.plot(x1, x, label='x')
plt.plot(x1, y, label='y')
plt.plot(x1, z, label='z')
plt.legend(loc='best') # 범례표시 'best' ==> 기본값
plt.xlabel('x') # x축 이름
plt.ylabel('y') # y축 이름
plt.title('My Graph') # 그래프 제목
plt.show() # X, Y, Z 모두 출력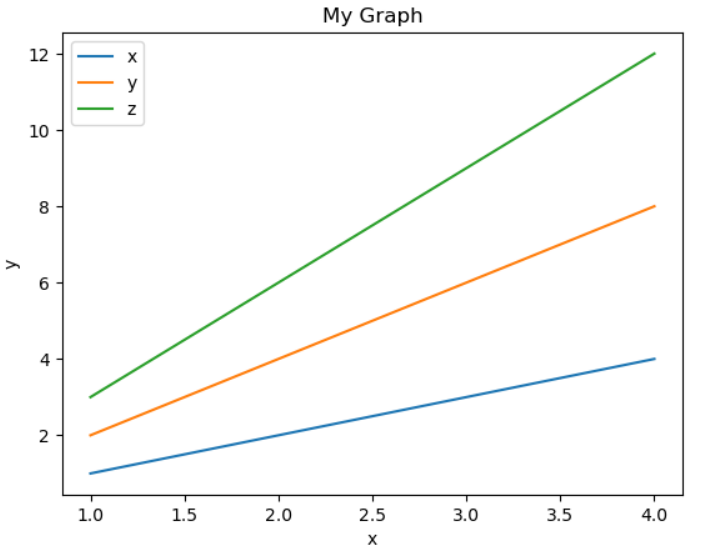
막대그래프 : bar()
x = [0,1,2,3,4,5]
y = [80,85,70,60,50,90]
plt.bar(x, y)
plt.show()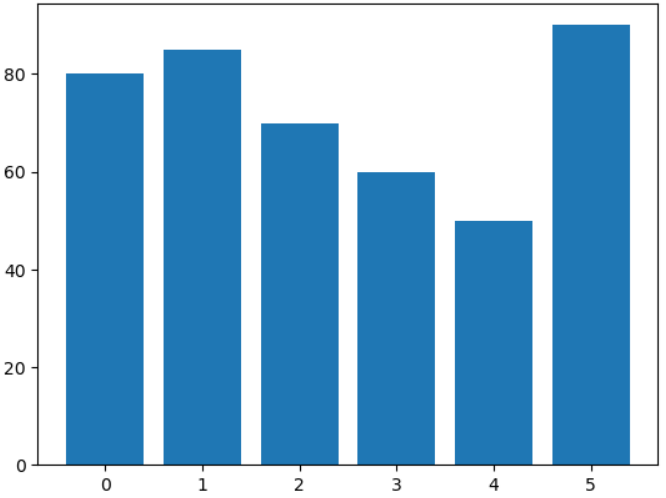
x = ['종현','기쁨', '준화', '수연', '주미', '수하']
y = [80,85,70,60,50,90]
plt.bar(x, y)
plt.show()
# 한글 표현하기
from matplotlib import rc
# 폰트 설정
rc('font', family='Malgun Gothic') # 시스템에 설정된 이름
x = ['종현','기쁨', '준화', '수연', '주미', '수하']
y = [80,85,70,60,50,90]
plt.bar(x, y)
plt.show()
데이터 분석 실습
- 전국사망교통사고 데이터 활용하여 분석
- 시각화
데이터 불러오기
import pandas as pddata = pd.read_csv('data/Traffic_Accident_2017.csv', encoding='euc-kr')
data# 데이터 확인
data.info()data[:5]
# 데이터를 간략하게 내용 확인하는 함수
# 맨 위에서부터 행 기준으로 5개 출력
data.head()
# 맨 아래에서부터 행 기준으로 5개 출력
data.tail()
요일별 교통사고 시각화 실습
교통사고 사망자 수 count
data['사망자수'].value_counts() # 특정 컬럼의 값들의 개수를 각각 출력
# 사람 수, 사고건수1 3958
2 97
3 8
4 1
5 1
Name: 사망자수, dtype: int64- 위 결과로 알 수 있는 점 : 사망자가 1인인 사고가 교통사고의 대부분을 차지하고 있음.
요일별 사고 건수 count
- 요일별 사고건수 확인
- 요일 순서대로(월 ~ 일) 출력
y = data['요일'].value_counts()
y = y[['월', '화', '수', '목', '금', '토', '일']]x = y.indexplt.bar(x, y)
plt.show()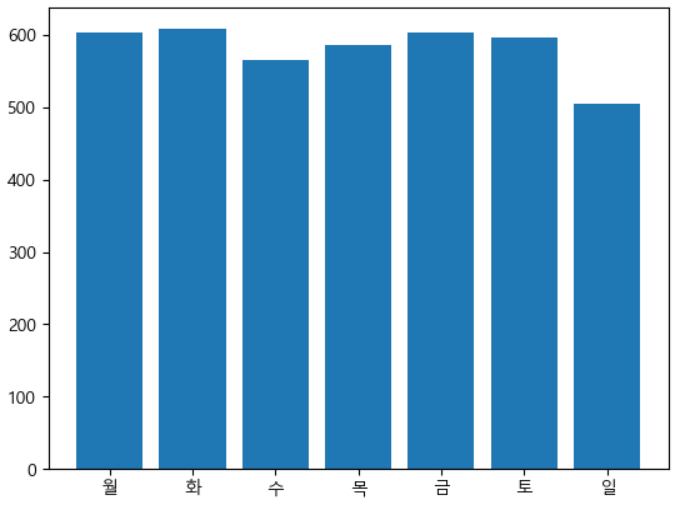
bar chart 옵션 추가
- y축 범위 설정(제한) : ylim
- x, y축 제목 설정 : xlabel, ylabel
- 전체 그래프 제목 설정 : title('제목')
# 옵션 설정
x = y.index
plt.bar(x, y)
# xlabel : '요일'
# ylable : '사고건수'
# title : '요일별 교통사고 건수'
# y축 범위 : 500 ~ 620
plt.xlabel('요일')
plt.ylabel('사고건수')
plt.title('요일별 교통사고 건수')
plt.ylim(500, 620)
plt.show()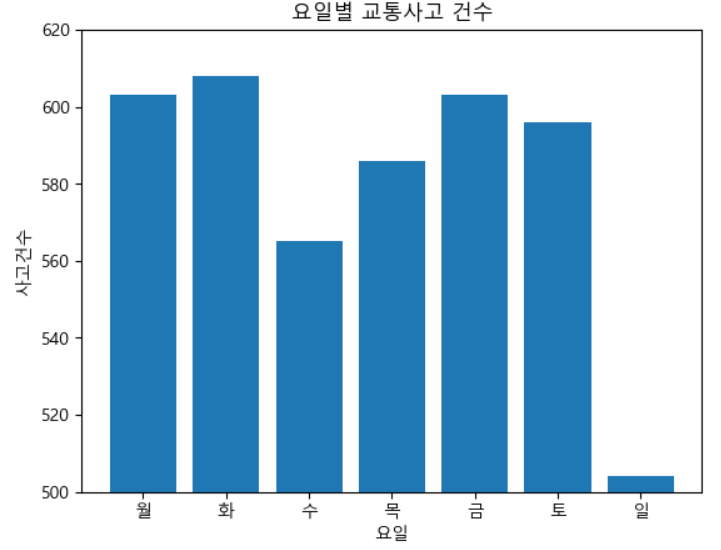
# 여러 개의 컬럼을 정렬하고 싶을 대,
# df.sort_values(by=['컬럼명1', '컬럼명2'], ascending=[False, True])
# by와 ascending에 입력할 원소의 개수는 같아야 함.
# pandas의 데이터프레임에서 모든 행, 열을 보고싶을 때
# 행
pd.set_option('display.max_rows', None)
# 열
pd.set_option('display.max_columns', None)data
'차대차' 사건 중 사상자 수가 많은 발생지 시도를 알아보고 시각화하기
- 차대차 사건
- 사상자 수
- 발생지 시도
데이터 위치 확인
- 사고유형 정보가 있는 컬럼에서 '차대차'인 행만 출력
- 발생지 시도에 있는 각각의 데이터 횟수 확인 ==> 확인용
- '사상자 수', '발생지 시도' 컬럼인덱싱
- 발생지 시도별로 묶어서 집계함수(총합) 연결한 후 시각화
data.columns
data['사고유형_대분류'].unique()
car_ac = data[data['사고유형_대분류'] == '차대차']
car_ac
car_ac['사고유형_대분류'].value_counts()
car_ac.columns
# 발생지시도, 사상자 데이터 접근하기
ac_place = car_ac[['발생지시도', '사상자수']]
ac_place
ac_place = car_ac[['사상자수', '발생지시도']].groupby(by='발생지시도').sum()
ac_place# x축, y축을 설정
x = ac_place.index
y = ac_place.values# 시각화 - 선 그래프 그리기
# plot()
plt.figure(figsize=(8, 5)) # figure => inch 단위
plt.plot(x, y)
plt.title('차대차 교통사고의 사상자 수 - 지역별')
plt.xlabel('지역명')
plt.ylabel('사상자수')
plt.grid()
plt.show()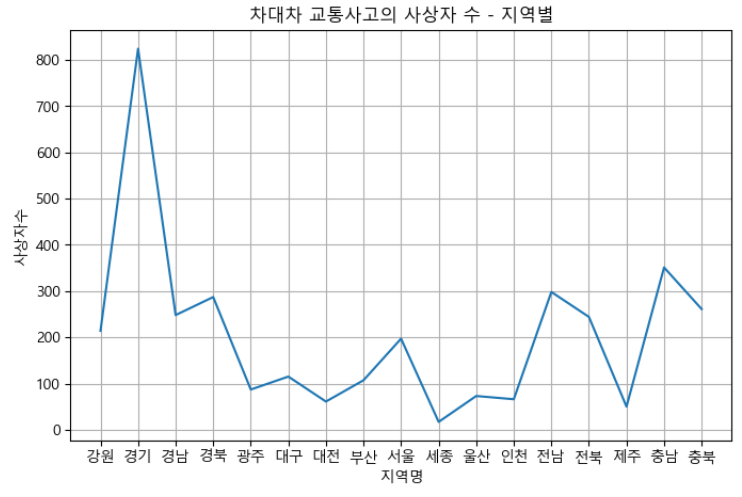
# y값을 이용하여 bar chart로 그리기
# bar chart는 1차원 차트
# 1차원 차트를 표현하기 위해서는 2차원의 numpy 배열을 1차원 리스트로 변환이 필요!
y_bar = []
for i in range(len(y)) :
y_bar.append(y[i][0])
y_bar[214, 824, 248, 287, 87, 115, 61, 107, 197, 17, 73, 66, 298, 244, 50, 351, 261]plt.figure(figsize=(8, 5))
plt.bar(x, y_bar)
plt.title('차대차 교통사고의 사상자 수 - 지역별')
plt.xlabel('지역명')
plt.ylabel('사상자수')
plt.show()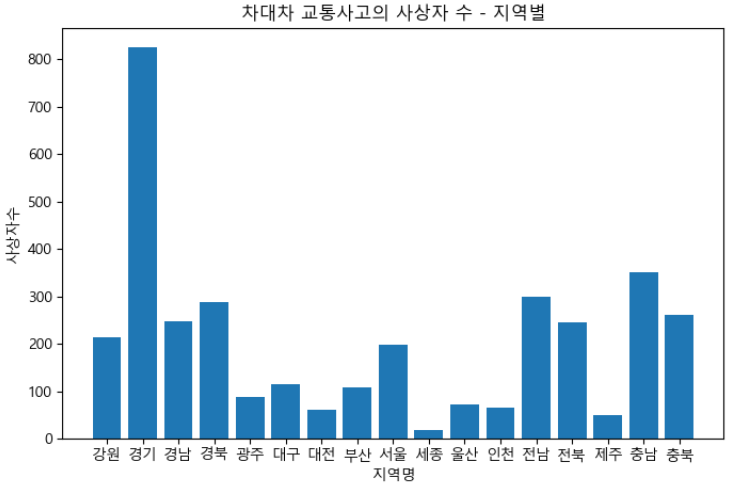
# 방법1)
# 차대차 사고가 발생한 1642개의 사건 중 시도별로 각각의 개수를 확인해보기
car_ac['발생지시도'].value_counts()
# 각 발생지 시도별로 사상자 수 합계를 확인해보기
car_ac2 = car_ac[['발생지시도', '사상자수']].groupby(by='발생지시도').sum()
car_ac2
# 사상자 수 데이터를 내림차순으로 정렬
x = np.arange(len(car_ac2.index))
y = car_ac2['사상자수'].sort_values(ascending=False)
# bar chart로 시각화 해보기
plt.figure(figsize=(8, 5))
plt.bar(x, y)
plt.xticks(x, y.index)
plt.xlabel('지역명')
plt.ylabel('사상자수')
plt.title('차대차 교통사고의 사상자 수')
plt.show()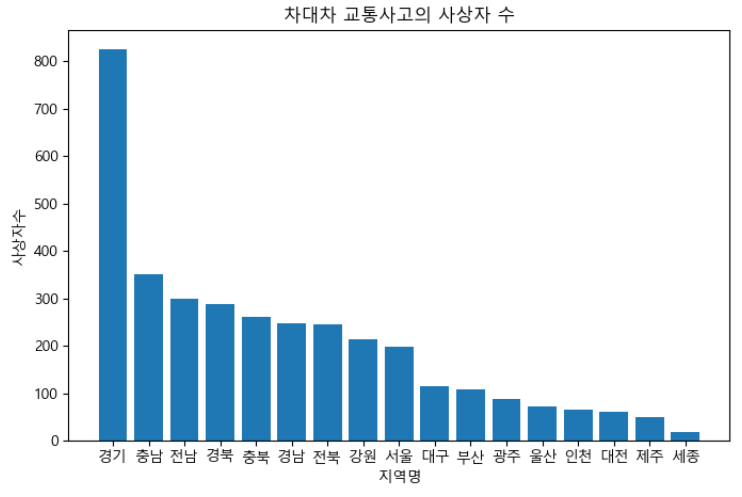
교통사고가 가장 많이 발생하는 시간대 알아보고 시각화 하기
# data 확인하기
data.columnsIndex(['발생년', '발생년월일시', '발생분', '주야', '요일', '사망자수', '사상자수', '중상자수', '경상자수',
'부상신고자수', '발생지시도', '발생지시군구', '사고유형_대분류', '사고유형_중분류', '사고유형', '법규위반_대분류',
'법규위반', '도로형태_대분류', '도로형태', '당사자종별_1당_대분류', '당사자종별_1당', '당사자종별_2당_대분류',
'당사자종별_2당', '발생위치X_UTMK', '발생위치Y_UTMK', '경도', '위도'],
dtype='object')time = data['발생년월일시'].astype('int64')
time
time % 100 # 시간 정보만 꺼내오기 위해서 %=(복합대입연산자)를 활용
time
# 시간을 카테고리화 시켜보자
# [0 ~ 23 시간을 표현] ==> 6개의 시간 구간
bins = [-1,4,8,12,16,20,23]
labels= ['0~4', '5~8', '9~12', '13~16', '17~20', '20~23'] # 시간대 이름 붙이기
result = pd.cut(time, bins=bins, labels=labels)
result
# 범주화 확인
result.value_counts()
# 해당하는 데이터로 파이그래프 그려보기
rs_data = result.value_counts().sort_index() # 시간대 정보로 정렬
rs_data
# pie chart 옵션설정하기
plt.figure(figsize=(5, 5))
plt.pie(rs_data, labels=labels, autopct='%1.2f%%')
# '%%', %를 문자로 넣겠다는 의미, 1.2f는 정수자리수.소수자리수 : 소수 둘째자리까지 표현
plt.title('시간대별 교통사고 발생건수')
plt.show()'언어 > Python' 카테고리의 다른 글
| [Python] 가장 최근 저장된 파일 불러오기 (0) | 2023.08.05 |
|---|---|
| 파이썬 라이브러리 시험 (0) | 2023.04.05 |
| Pandas (0) | 2023.04.04 |
| Numpy 실습 - 영화 평점데이터 분석하기 (0) | 2023.04.03 |
| Numpy (0) | 2023.04.01 |


댓글